Authentication
http://code.google.com/apis/youtube/developers_guide_protocol.html
It is recommended that you include the proper authentication headers in all of your requests even if those requests do not explicitly require authentication.
A request must include the X-GData-Key and Authorization headers.
The X-GData-Key header specifies your developer key, a value that uniquely identifies your application(s). The Authorization header specifies a token that you obtain for each user using one of two authentication schemes, AuthSub or ClientLogin. Headers are like this:
| AuthSub | ClientLogin |
| Authorization:AuthSub token=<authentication_token> X-GData-Key: key=<developer_key> | Authorization:GoogleLogin auth=<authentication_token> X-GData-Key: key=<developer_key> |
(1) Functions supported in AuthSub
http://code.google.com/apis/accounts/docs/AuthForWebApps.html
(1.1) AuthSubRequest
A call to this method sends the user to a Google Accounts web page, where the user is given the opportunity to log in and grant Google account access to the web application. If successful, Google provides a single-use authentication token, which the web application can use to access the user's Google service data. This is done by using GET to a specific formatted URL.
Sample URL
https://www.google.com/accounts/AuthSubRequest?scope=http%3A%2F%2Fgdata.youtube.com&next=http%3A%2F%2Fzhguo.blogspot.com
(1.2) AuthSubSessionToken
A call to this method allows the web application to exchange a single-use token for a session token.
Sample request
curl https://www.google.com/accounts/AuthSubSessionToken --header ‘Authorization: AuthSub token="token"’
Response
Token=DQAA...7DCTN
Expiration=20061004T123456Z
(1.3) AuthSubRevokeToken
A call to this method revokes a session token. Once a token is revoked it is no longer valid.
Sample Request
curl https://www.google.com/accounts/AuthSubRevokeToken --header ‘Authorization: AuthSub token="token"’
(1.4) AuthSubTokenInfo.
A call to this method verifies whether a specified session token is valid and returns data associated with the token. This operation applies to both one-time-use and session keys.
Sample request
curl https://www.google.com/accounts/AuthSubTokenInfo --header 'Authorization: AuthSub token="CO7xhO-6GhDT5f2tAwd"'
Sample response
Target=http://www.yourwebapp.com
Scope=http://www.google.com/calendar/feeds/
Secure=true
(2) ClientLogin
http://code.google.com/apis/accounts/docs/AuthForInstalledApps.html
Before using ClientLogin, you must have an existing Google account. The POST request should be structured as a form post with the default encoding application/x-www-form-urlencoded. Parameters should be included in the body of the post.
Action URL parameter: https://www.google.com/accounts/ClientLogin
Sample request format:
POST /accounts/ClientLogin HTTP/1.0
Content-type: application/x-www-form-urlencoded
accountType=HOSTED_OR_GOOGLE&Email=jondoe@gmail.com&Passwd=north23AZ&service=cl&source=Gulp-CalGulp-1.05
CURL command
curl --location https://www.google.com/youtube/accounts/ClientLogin
--data 'Email=username&Passwd=password&service=youtube&source=Test'
--header 'Content-Type:application/x-www-form-urlencoded' -i
Sample Response:
SID=DQAAAGgA...7Zg8CTN
LSID=DQAAAGsA...lk8BBbG
Auth=DQAAAGgA...dk3fA5N
(3) Difference of two mechanisms
To use ClientLogin, a third-party application must own Youtube’s username and password of every user. Then the third-party application can do anything the end user can do. This mechanism is convenient for third-party apps to use because it does not require much intervening from users. However, it requires trust of users who may be afraid that their person information is not stored appropriately.
To use AuthSub, a third-party does not need to own Youtube’s username and password of user. Instead, the user will be redirected to a web site from google to authorize third-party app’s access to user’s account. At first, third-party app is given a one-time access key which can be used to exchange a session key that can be used longer. This method is more secure for users at the cost of manually authorizing access requests.
Some development detail
(1) Some videos are not allowed to be embedded in third-party applications.
In the feed of these videos, mediagroup::content element does not exist!!! I manually construct URL by concatenating http://gdata.youtube.com/feeds/api/videos/ and video id and try to embed it into my app. As I expect, it does not work. However, I figured out a method which can work around this problem. I concatenate http://www.youtube.com/swf/l.swf?video_id= and video id and it works.
(2) Some videos are not allowed to be commented by some users. These videos should be handled carefully.
http://gdata.youtube.com/feeds/api/videos/gmNbl5ZTBZE
(3) Duplicate elimination
If you upload the same video clip more then once using different metadata, Youtube can figure it out and all uploads but the first one will be rejected. I am not sure how they compare two different video clips, maybe using MD5 to calculate a signature. The duplicate uploads are still displayed in your account. And all metadata is preserved except the video clip itself. The only difference between original upload and following duplicate uploads is that you can not play duplicate video clips.
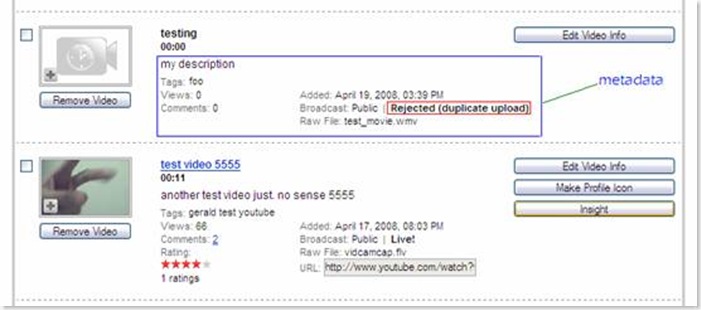
As shown in above picture, metadata (e.g. description, tags, views, published time…) are still there. But the video clip itself is rejected
(4) OpenSearch support
If you search videos on Youtube, in returned feed openSearch extension is supported:
<openSearch:totalResults>274842</openSearch:totalResults>
<openSearch:startIndex>1</openSearch:startIndex>
<openSearch:itemsPerPage>25</openSearch:itemsPerPage>
(5) Navigation of many returned results.
In returned feeds, if not all results are returned, there should be a link element in the feed. It is like this:
<link rel="next" type="application/atom+xml" href="http://... "/>
<link rel="previous" type="application/atom+xml" href="http://... "/>






