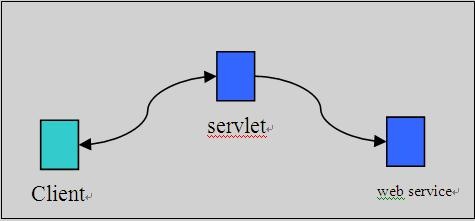
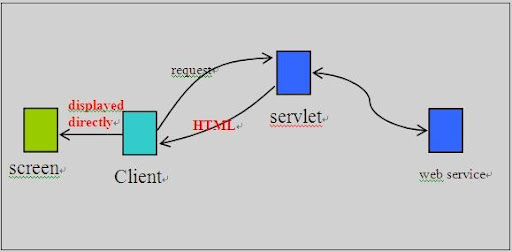
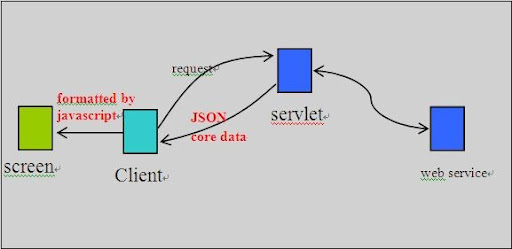
Recently, I am focusing on providing visual widgets to ease composition of Karajan workflow. It is not practical to build the application from scratch. I have surveyed several prevailing javascript/Ajax frameworks including qooxdoo, prototype, jQuery, Ext, mootools.
Survey of js frameworks:(1) jQuery(
http://jquery.com/)
As its name implies, its emphasis is query. At first sight, the framework is beautiful and concise. It supports CSS dom selector and XPath syntax. Besides, it provides further convenient selection syntax. Some examples follows:
$("a")
$("a[@name]")
$("a[@href=content/resources]")
$("ul > li")
$("ul li")
$("ul .list > a")
$("#output")
More examples:
$("li:eq(0)") //gets the first item
$("li:lt(3)") //get the first three items
$("li:not(.groove)") //get li elements without class groove
Beautifully, right? We can do lots of work by code of just several lines!!
Chaining: Most functions return a jQuery object so that you can directly invoke more functions.
$('form#login')
// hide all the labels inside the form with the 'optional' class
.find('label.optional').hide().end()
// add a red border to any password fields in the form
.find('input:password').css('border', '1px solid red').end()
// add a submit handler to the form
.submit(function(){
return confirm('Are you sure you want to submit?');
});
No matter whether you like this kind of code or not, it is functionality provided by jQuery. I prefer to use multiple lines of code and self-documenting variable names which look clearer.
Plug-ins: jQuery is blooming considering number of its plug-ins. Plug-ins increase sharply recently and many developers contribute to it.
However, jQuery does not excel at UI. In other words, if you want to build fancy user interface, jQuery is not the first choice.
(2)
Ext(
http://extjs.com/)
Originally, Ext was based on YUI and it was developed as extension for YUI. Then, Ext broke away from YUI and was developed as an independent project.
Its emphasis is abundance of UI widgets. It provides many fancy and convenient UI widgets which can be used easily to build our own GUI. The configuration of UI widget looks like this:
var panel = new Ext.Panel({
title: "This is title",
width: 400,
height: 300,
border: true,
layout: "accordion",
items: [ .... ]
});
It is more convenient than invocation of bunch of functions to set values of properties(e.g. panel.setwidth(400); panel.setheight(400);...).
Not long ago, combination of jQuery and Ext was announed which is good news to web application developers. However, process of the combination is kind of slow and support of jQuery in Ext 2 is limited and buggy.
(3)Qooxdoo
This framework is sort of comprehensive which includes almost all common functionalities. Documentation is not bad. It is growing rapidly and seems promising.
However, current version of this framework is 0.7, which means it is still in beta phase and not appropriate for production use. Apart from that, it aims to control the whole web page by Qooxdoo. So it is difficult for end users to directly access/modify underlying dom element. This drawback is annoying because inevitably users sometimes want to manipulate underlying elements directly.
(4)Dojo(http://dojotoolkit.org/)
This framework is so comprehensive and complex. It is the most powerful framework I have ever seen. It provides lots of functionalities: UI widgets, event system, offline support, presentation... As a result, the framework is sort of bloated and cumbersome. Bugs are not rare... Besides, documentation is done badly which makes development more difficult.
Maybe, in the future, Dojo will become outstanding in term of functionality, performance and documentation. But for now, it is far from that.
(5)Prototype(http://www.prototypejs.org/)
This framework adds basic OO features to javascript, e.g. inheritance. It is actually a language(javascript) extension library. Moreover, it extends some built-in objects (String, Array...) of javascript to offer more convenient functionalities. Script aculous(http://script.aculo.us/) is built on top of prototype and provides UI widgets.
I read some articles about prototype and it seems that the support for OO features has problems in some situations.
Karajan Workflow Composition
Anyway, finally I chose Ext as my javascript framework.
Some screenshots about the workflow composition panel:
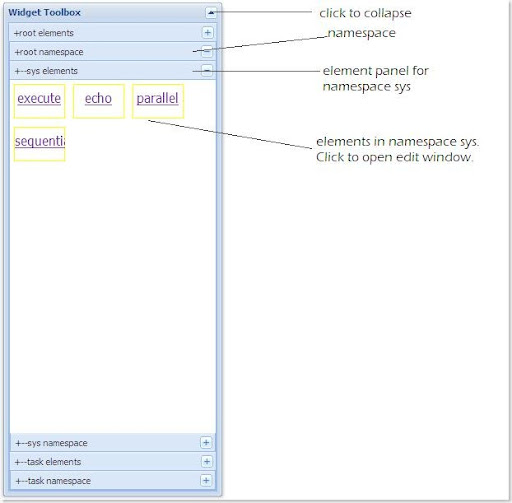
The panel is organized according to namespaces. So if user knows the namespace of an element, it is effortless to find the corresponding widget in the toolbox. And all main panels structured into accordion layout. If user clicks the title bar of a panel, that panel is expanded and all other panels are collapsed.
Karajan workflow element edit panel:
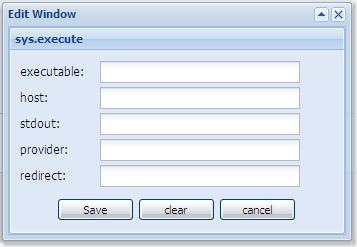
After values of various properties are typed, the xml document corresponding to the element will be automatically inserted into output panel. For sys.execute element, the xml snippet looks like this
<sys:execute executable="..." host ="..." stdout="..." provider="..." redirect="..."/>
Currently, all values are enclosed by double quotation marks. The reason is that Karajan workflow is XML document in nature. For xml document, value of every attribute/property MUST be enclosed by quotation marks.
For other workflow languages,this is not always correct because types of some properties are integer/boolean and these values should not be enclosed by quotation marks.
After user clicks "Save" button, the generated xml snippet is inserted into output panel. The xml snippet is not simply appended to the output panel. Instead, it is inserted into current cursor position.
Scalability and Maintainability
During design, I always keep a principle in my mind: built-in elements of Karajan are abundant and users can add their own customized elements. As a result, the addition of elements to widget window/toolbox should be easy and scalable.
The configuration is a javascript object:
{
elements: {},
namespaces: {
sys: {
namespaces: {
file: {
elements: {
read: {
properties: ["name"],
widgetProps: { }
},
write: {
properties: ["name", "append"],
widgetProps: {}
}
},
namespace: {}
}
},
elements: {
execute: {
properties: ["executable", "host", "stdout", "provider", "redirect"],
widgetProps: {height:"40px, width:"40px"}
},
echo: {
properties: ["message", "nl"],
widgetProps: {}
},
parallel: {
properties: [],
widgetProps: {}
},
sequential: {
properties: [],
widgetProps: {}
}
}
}
}
}
In Karajan, namespace is supported. For every namespace, there are two properties: elements and namespaces. Property elements contains information about those elements directly in the namespace. Property namespaces contains information about sub namespaces.
In above example, namespace sys contains elements execute, echo, parallel and sequential and it contains sub namespaces file. Then namespace file contains elements read and write and it contains no sub namespaces.
For every element, it contains two properties: properties and widgetProps. Property properties contains list of parameters about the elements. Property widgetProps contains configuration information about how to display the corresponding widget in the toolbox window.
In above example, element execute has properties executable, host, stdout, provider and redirect.
To add more elements, I just need to modify the configuration object shown above. Obviously, it is convenient to modify it.
Improvements we can do in the future
(1) Now I list all properties of an element in the edit panel. For some elements, number of properties is more then ten. But only some properties are used frequently and others are seldom used. In the future, we can first hide the optional properties and only display the necessary properties. If user wants to use all properties, we show those optional properties as well.
(2) Search functionality. Number of elements may be enormous and it is painful to browse all namespaces to find the desired element.
However, this improvement is not necessary. Official website of CogKit provides reference manual for Karjan workflow and detailed information about all elements of Karajan is included. So user can first consult the reference manual for detailed information on the desired element. Then the user will get the fullname of the element which includes name of namespace in which the element is located. According to namespace, it is very easy to find the corresponding widget in the toolbox.